

The innovation behind AI at Scale
In the blog post Demystifying AI at Scale, we gave a quick overview of how Microsoft and an increasing number of our customers are leveraging the trend of large-scale AI models to support a variety of applications. We believe that every organization in the world should benefit from the power of these models, which is why Microsoft’s AI at Scale initiative is making these large models – and the systems and infrastructure to enable training and utilization – available as a platform.
Fueling this initiative is Microsoft’s cutting-edge research on AI, guided by real-world applications and scenarios. Microsoft Research has been at the forefront of AI advancements with breakthroughs across natural-language processing, computer vision, speech recognition and more. In 2018, inspired by early research developments in the large-language model space, we began utilizing these large-scale models in services ranging from Microsoft Bing to Microsoft 365. The results were extremely promising. It was clear though, that most organizations would find our outcomes difficult to duplicate due to barriers such as access to massive-scale infrastructure.
So, we decided to develop platforms, tools and a supercomputing infrastructure that would allow any developer to build and scale their own AI innovation. At the Microsoft Build 2020 developer conference, we announced the Microsoft AI at Scale initiative, dedicated to giving all organizations access to these powerful AI models.
Since then, continued progress in both fundamental and applied AI research has translated into ever-more transformative products, services and operations – which Microsoft is committed to making accessible to all.
This blog post explores the innovations behind the Microsoft AI at Scale initiative.
AI-enhanced Microsoft products and services
Every day, millions of people benefit from Microsoft’s powerful large-scale foundational models available across more than 80 enterprise and consumer scenarios. For example, our language-understanding capability allows you to use natural language to find relevant answers to open domain questions across 100 languages using Bing or within Microsoft Word. With the same AI at Scale technology, Microsoft Dynamics 365 provides relevant answers, insights and actions employees can take for their own business operations.
Thanks to language generation, Suggested reply makes instant messaging in Microsoft Outlook and Microsoft Teams a richer experience. Using Microsoft Editor, writers can use intelligent tools to craft more polished prose. Our language-generation model is also capable of knowledge and synthesizing software code. Viva Topics automatically organizes content and expertise across an organization making it easier for people to find information and put knowledge to work, while GitHub Copilot helps developers convert natural language into code using OpenAI Codex.
Features using AI at Scale






Beyond language models, multimodal intelligence across text, image and layout is enabling beautiful slide design recommendations in Microsoft PowerPoint Designer. This multimodal capability can find relevant answers in natural language, visualize the answer presented in images, and refine search with visual objects from images in Bing question-and-answer and multimedia-search experiences.
AI at Scale technology stack
The same AI at Scale stack used in Microsoft products and services are available for organizations through Microsoft Azure. Before we explore how you can build these kinds of experiences within your own products and services, let’s dive into the stack’s components.
APIs
One of the simplest ways to use these powerful pre-trained models is through a managed API. Microsoft’s models are available as API endpoints through Azure Cognitive Services, Azure OpenAI Service and Azure Cognitive Search. This gives you access to the models without having to worry about infrastructure and hosting details.
Azure Cognitive Services
Azure Cognitive Services are cloud-based services with REST APIs and client library SDKs to help developers build cognitive intelligence into applications. This enables you to build cognitive solutions that can see, hear, speak, understand and even make decisions.
- Azure Cognitive Services for Language provides APIs for several downstream tasks such as machine translation, sentiment analysis, named-entity recognition and text summarization, providing easy access to our large-scale language models.
- Azure Cognitive Services for speech and vision tasks provide APIs for visual and multimodal tasks such as visual question and answering, image captioning, object detection and speech recognition and translation.
- Fine-tune your model for your domain or data with APIs such as custom text classification, custom vision and custom named-entity recognition.
Azure OpenAI Service
Azure OpenAI Service, currently in private preview, will provide organizations access to OpenAI’s powerful natural-language generation model GPT-3, with the security, reliability and enterprise capabilities of Azure. Some early customers are using the service in creative ways.
Azure Cognitive Search
Semantic search, offered through Azure Cognitive Search, is a query-related capability that brings semantic relevance and language understanding to search results. Organizations including Igloo Software and Ecolab use it to empower customers and employees alike. When enabled on your search service, semantic search extends the query execution pipeline in two ways: It adds secondary ranking over an initial result set, promoting the most semantically relevant results to the top of lists; and it extracts and returns captions and answers, which you can render on a search page.
Pre-trained AI models
We’re building upon our already strong collaboration between research and engineering to achieve new modeling techniques for language breakthroughs and to continuously integrate these into our large-scale foundation model family. For instance, the advancement of self-supervised learning techniques enables AI systems to learn from orders of magnitude more data, different languages of data and different modalities of data, enabling much larger and accurate models. Below are some exciting achievements.
Natural-language understanding
Our large-scale foundation model family started with monolingual models for language understanding. Microsoft was the first company exceeding human parity on the SuperGLUE benchmark by bringing in DeBERTa, which was integrated into the Turing NLRv4 model. The language-understanding capability was further topped by the Turing NLRv5 model, which recently became the new leader on both the GLUE and SuperGLUE leaderboards. Expanding model training to support multiple languages, the Turing ULRv5 multilingual model, with support for 100 languages, reached the top of the XTREME leaderboard, a benchmark for evaluating multilingual language understanding.
Though these large-scale pretrained language models have made significant breakthroughs in language understanding, they still struggle with commonsense knowledge gathered in our daily lives. Microsoft KEAR achieved this breakthrough in commonsense that surpassed human parity in the CommonsenseQA benchmark in December 2021.
Natural-language generation
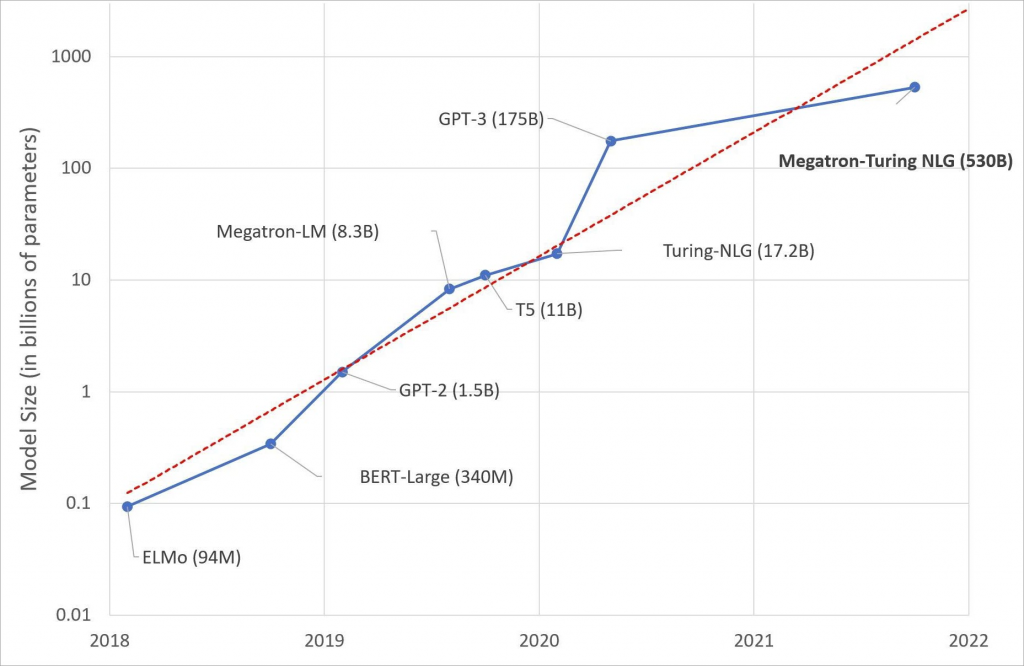
In February 2020, Microsoft announced the Turing Natural Language Generation (T-NLG), the largest model ever published at the time, with 17 billion parameters. It outperformed then-state-of-the-art models on a variety of language modeling benchmarks on tasks such as summarization and question and answering. This laid the foundation for the platform capability enabling us to train increasingly larger models.
Last year, our partnership with OpenAI brought to the mainstream GPT-3 models that light up innovative product experiences such as no-code/low-code app creation via conversation to code in Microsoft Power Apps. We then expanded this generative capability to 100 languages with a unified multilanguage generative encoder-decoder model (Turing ULG) that brings in research innovation in and DeltaLM. This model is still top of the leaderboard in the Large-Scale Multilingual Machine Translation challenge.
In 2021, through Microsoft’s partnership with NVIDIA, we announced the Turing Natural Language Generation model (MT-NLG), the world’s largest generative-language model. Pushing the envelope in model scaling, it achieves a strong level of accuracy in major categories of natural-language tasks, including common-sense reasoning, reading comprehension, text prediction and language inference in the setting of zero-, one- and few-shots without searching optimal shots.
Language to code generation
In terms of more structured symbolic machine language, the Codex model extended the GPT-3 from natural-language generation to code generation by training on billions of lines of source code and natural-language text to power GitHub Copilot, a new AI pair programmer that helps you write better code.
Multimodal
Given the great progress in powerful large-scale language models, we understood that it was critical to incorporate other modalities into our models. These multimodal models can reason jointly across multiple input formats including text, layout, images and video.
Our new Vision-Language model topped the NoCaps benchmarks surpassing human baselines. And our Turing Bletchley 2.5-billion parameter universal image-language representation model achieves outstanding performance in image-language tasks in 94 languages. It even understands text in images without using OCR technologies, directly identifying similar images with encoded image vector. Furthermore, we trained a foundational computer-vision model, called Florence V1.0, which achieves state-of-the-art performance for a wide range of computer-vision tasks covering over 40 benchmarks.
One important approach to advancing model capabilities is the training of expert models with subtasks using an ensemble method, named Mixture of Experts (MoE). The MoE architecture also preserves sublinear computation with respect to model parameters that provides a promising path to improve model quality via scaling out trillions of parameters without increasing training cost. We have also developed MoE models to our pretrained model family accelerated with DeepSpeed. (DeepSpeed details can be found below.)
These large-scale pre-trained models become platforms and can be adapted to specific domains or tasks by using domain-specific data in a privacy-compliant manner. We refer to this collection of base and domain-adapted models as “AI models as a platform,” which can be used directly to build new experiences with zero-shot/few-shot learning or used to build more task-specific models through the process of fine-tuning the model with a labeled dataset for the task. In a similar fashion, you can domain adapt or fine-tune these models with your own enterprise data privately within the scope of your tenant and use them in your enterprise applications to learn representations and concepts unique to your business and products.
Azure Machine Learning service
Azure Machine Learning service is the enterprise-grade service on the Azure cloud supporting the end-to-end machine learning development lifecycle. It provides a highly productive experience for building, training and deploying machine learning and deep-learning models faster at scale. It enables team collaboration with experiment tracking, model-performance metrics collection and industry leading MLOps (DevOps for machine learning). Azure Machine Learning service supports model training and deployment across all major deep-learning frameworks and runtimes, such as our optimized ONNX Runtime. Azure Machine Learning service enables the effective usage of the underlying Azure AI infrastructure and system optimizations.
Machine learning acceleration software
Large models with billions or even trillions of parameters require a host of optimization and parallelization strategies to be trained efficiently. So, we developed a set of optimization techniques, such as the Zero Redundancy Optimizer (ZeRO), and open sourced them into a PyTorch acceleration library called DeepSpeed since 2020. DeepSpeed continues to trailblaze with an extreme focus on speed, scale, efficiency, usability and democratization of large-scale model training and inferencing.
Some of the new features in DeepSpeed include the ability to efficiently train sparse models using the MoE machine learning technique, boosted data efficiency and training stability through curriculum learning, fast and efficient distributed inference for large models, and specialized high-performance GPU kernel library for widely used operators, such as standard and sparse transformers.
ZeRO-Infinity is another feature in DeepSpeed. It breaks the GPU memory wall to enable training models with trillions of parameters by offloading parameters and state to the NVMe disk storage, enabling you to train large models on a single GPU or a single node with a few GPUs. For example, you can fine-tune a GPT-3-sized model on a single node thanks to ZeRO-Infinity to create the ability to train very large models on more modest hardware. Using DeepSpeed optimizations our internal production workloads have seen anywhere from 2x to 20x bigger model scale and fast training for large models.
The following video shows how ZeRO-Infinity efficiently leverages GPU, CPU and NVMe altogether by 1) partitioning each model layer across all data processes, 2) placing the partitions on the corresponding data parallel NVMe devices and 3) coordinating the data movement needed to compute forward/backward propagation and weight updates on the data parallel GPUs and CPUs, respectively.
ONNX Runtime (ORT) is another dimension in optimization for both training and inferencing where we compile deep-learning model execution graphs and determine the optimal execution by fusion of operators and a library of highly efficient GPU kernels. Now, you can combine the graph-level execution optimizations from ONNX Runtime and the algorithmic optimizations in DeepSpeed — using the Torch ORT Module that Microsoft contributed to the PyTorch open source — making training even more efficient. In our benchmark tests we noticed an 86% improvement in performance for fine-tuning Hugging Face models when DeepSpeed and ORT were combined.
We’re thrilled to see some of the leading frameworks and libraries, such as PyTorch Lightning, FairScale and Hugging Face, adopt DeepSpeed and ORT. DeepSpeed was also core to Microsoft’s collaboration with NVIDIA in training the largest language model in the world, a 530-billion parameter model. Initiatives like BigScience Workshop leverage the DeepSpeed technology to build large-scale multilingual multitask models with a globally open community-based approach.
ONNX Runtime, for several years now, has been supported for inferencing on both CPU and GPUs, delivering up to 17x speedup through built-in optimizations. We expanded the optimizations to cover deployment of models beyond the cloud and PC-based edge devices to include ONNX Runtime for mobile and the ONNX Runtime for the web for running inference models locally on Android and iOS devices or in a web browser with a small memory and storage footprint.
We also developed other algorithmic innovations, such as Low-Rank Adaptation of Large Language (LoRA), which helps to further reduce memory footprint while fine-tuning large models by having to retrain only a small subset of the parameters (10,000x lower in some cases) instead of all the parameters in the fine-tuning process, saving 3x in compute requirement. Similarly, LoRA is useful in the deployment of several independent instances of fine-tuned models based off the same large pretrained model sharing the base model parameters and has a small subset of parameters for each instance or downstream task.
These innovations have enabled efficient use of compute resources to enable training with fewer resources and allowing researchers to experiment with even larger models to advance the state of the art for various tasks and without breaking the bank.
Infrastructure
Finally, building large-scale AI requires a scalable, reliable and performant infrastructure. Azure offers best-in-class supercomputing infrastructure in the public cloud for AI workloads of all sizes. It supports GPU acceleration for popular frameworks such as TensorFlow, PyTorch and others from a single GPU, up to the flagship NDv4-series virtual machine, which offers eight NVIDIA A100-80GB GPUs fully interconnected by the fastest networks inside and across the machines. This system is currently rated on the top 10 list of the fastest supercomputers in the world and is the first public cloud-based system on this list. On top of these AI compute resources, Azure also offers a wide range of storage and networking solutions essential for AI training workloads.

Looking forward
The scale of AI models continues to increase, enabling capabilities that once seemed impossible and resulting in state-of-the-art benchmark records. Hardware and infrastructure capabilities will continue the pace of growth. As techniques, such as MoE, mature further in terms of tooling and efficiency, we’ll see more advancements in AI at Scale, including an increase in single models trained on diverse datasets to perform multiple tasks at scale.
And the same energy we saw around large-language models has spilled over into other domains, such as computer vision, graph learning and reinforcement learning. Models will be increasingly multimodal in nature, learning representations across multiple input formats across combinations of audio, images, video, language, structured tabular data, graph data and source code to deliver richer experiences.
We’ll continue to bring more of these powerful AI models as a platform to customers and partners across our different channels, whether through integrated experiences across the Microsoft product portfolio or easy-to-use APIs like Azure Cognitive Services, Azure Semantic Search and the new Azure OpenAI API. In addition, we’ll continue working with the academic and research community on further improving the responsible AI aspects in the training and usage of our models through the Turing Academic Program.
Our commitment to sharing the key building blocks for these models as a platform via open source remains strong. We continuously innovate in DeepSpeed, ONNX Runtime and the training recipes in Azure Machine Learning to push the boundaries of efficiency to train and serve the models and increase scale of models to trillions of parameters. We’ll continue to democratize the access and ability to train or adapt ever-larger base models and deploy these models to the cloud.
The convergence of innovations in infrastructure, machine learning acceleration software, platform service, and modeling powered by cloud technology has created the perfect conditions to accelerate innovation in AI. This will improve access to this powerful technology to enable every company to become an AI technology company and to help you achieve your business goals more effectively. We look forward to seeing the exciting applications and experiences you can build using the technology stack for AI at Scale.
Get started with the AI at Scale platform
Developers have access to this advanced AI technology today through the following range of tools and resources:
API services
- APIs over powerful machine learning models: Azure Cognitive Services for language, computer vision and more, Azure Cognitive Search and Azure OpenAI Service advanced-language models.
Pre-trained AI models
- Customers interested in using our base Turing models directly for their own specific task can submit a request to join the Turing Private Preview. In addition, we make our models available to academics and researchers for collaborative projects via the Microsoft Turing Academic Program.
Machine learning services
- Full-stack machine learning development/deployment platform: Azure Machine Learning services for experiment tracking, distributed training, curated containers, MLOps, Responsible AI tools and model hosting for inference. We also offer PyTorch Enterprise for Azure, which includes long-term support, prioritized troubleshooting and integration with Azure solutions.
- Cloud based no-code or low code systems: Power Apps/AI Builder and Azure Automated Machine Learning.
Infrastructure
- Cloud infrastructure: Azure GPU instances and clusters with optional InfiniBand connectivity; range of cloud storage options with Azure Blobs or Azure Data Lake Storage and Azure SQL databases; data warehousing, governance and analytics across relational databases and unstructured data lakes on Azure Synapse.
Tools
- Open-source machine learning acceleration software: DeepSpeed and ONNX Runtime for training and inferencing including support for mobile and web.
- Developer tooling: Visual Studio Code is the most popular open-source code editor/debugger with extensions for Python development and machine learning. GitHub CodeSpaces is a hosted development environment on the cloud powered by Visual Studio Code.
Gopi Kumar, Jiayuan Huang, Nguyen Bach and Luis Vargas, Office of the CTO team at Microsoft, contributed to this article.
Top image: Photo courtesy of Microsoft.







