

Perhaps you’re curious: you’ve heard the term “Differential Privacy,” and want to know exactly what that means for you, a machine learning practitioner. On my second rotation with Microsoft’s AI Development Acceleration Program (MAIDAP), I was lucky enough to work with the Responsible AI team on Microsoft’s open source differential privacy toolkit Smartnoise. Now I get to share some of what I’ve learned with you.
Skittles, M&M’s, and Differential Privacy

We’ll start at the beginning with an invitation, a framing of the topic that might feel slightly new. I invite you to think of differential privacy as a promise, and not as a technology. The group of technologies that we call differential privacy are actually a group of mechanisms that attempt to support this promise – the group of technologies is a means to an end, and that end is Differential Privacy (DP).
Separating differential privacy (the theory, or “promise”) from differentially private mechanisms (the application) gives the approach unique power. Unlike many privacy schemes whose guarantees are tied to a scenario, a differentially private algorithm has a guarantee (its “power”) that allows privacy to be quantified to a precise degree — a variable we call epsilon.
Wait, epsilon? Let’s slow down! Before we discuss the mathematical foundations of DP, let’s frame the “differentially private” notion to improve our intuition with a slightly sillier, perhaps more memorable example – I like to think about DP in terms of Skittles.
Imagine you have a bowl of very important Skittles. For whatever reason, you are releasing general information about each Skittle (color, weight, size, ovally-ness) so that people get a sense of the distribution of Skittles in your bowl. However, you are worried about the privacy of your important Skittles, and that concerns you deeply.
Most importantly: You know that there is at least one M&M in the bowl.
You worry that people will be able to identify whether a specific “Skittle” is actually the M&M using the data you release. In fact, you know that they could, because M&M’s are a little bit different from Skittles. (And it’s nobody’s business anyway if you like to put an M&M in with the Skittles…)
Before you release all this Skittle information, you want to promise that some hypothetical bowl of Skittles that has an M&M in it is, to any malicious snacker, virtually indistinguishable from a bowl of Skittles without any M&M’s at all. That promise — that an individual’s data is anonymous to a specific degree — is the promise of differential privacy.
Protecting M&Ms with Math
Let’s discuss the formal definition of Differential Privacy briefly, and then provide some intuition. Please stick with me through the equation; it may initially appear intimidating, but as you learn more about the DP mechanisms, you will begin to appreciate its beauty and even acknowledge its simplicity. By understanding this formula, you’ll have a mathematically rigorous way to quantify privacy – rather than just calling something “private.”
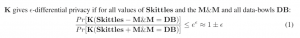
We have put the DP equation in terms of our silly example, and so more rigorously defined our intuition. Let’s say that we have a bowl of Skittles, and we understand our feature space well enough that we can imagine all possible data-bowls. Finally, we take a single M&M, and our database access function, or mechanism, K.
The differentially private promise is as follows: our method K is differentially private if, when we apply it to a data-bowl without our M&M, and a data-bowl with the M&M, the difference in the probability of both outputs from K is less than some small number epsilon.
But how do you do this? The “how” involves coming up with a differentially private mechanism that ensures the promise above is kept for a given epsilon. For a highly sensitive dataset, you might choose a very small epsilon, and for a less sensitive dataset, you could allow a larger epsilon. The important part is that the promise is kept.
Mechanisms (like K) rely on adding a very small, specific amount of random noise to a data query or distribution. That amount of noise is tuned directly with the epsilon that we discussed above. So how much random noise is added? Exactly enough to ensure that a malicious snacker cannot ever be sure which piece of candy is the M&M. The malicious snacker only has direct access to the data you release — they don’t have the original bowl of Skittles. Because the data you release has enough random noise to ensure the promise of differential privacy, the malicious snacker can never be sure. You can rest easy knowing that the M&M is safe.
Furthermore, you should still be able to provide enough information for any innocent snackers to gather aggregate information about your Skittles – like the amount of red versus green Skittles – and the resulting distributions of all your features should be relatively unaffected by the small amount of random noise you added.
Problem Statement
Skittles and machine learning pipelines aren’t so different – both are pretty sweet! And both can get you into some pretty sticky situations if used improperly or without care.
Jokes aside, one of the primary difficulties in adopting differential privacy in practice is deciding on exactly the right DP mechanism for a given scenario. There are many ways to fulfill the DP promise — approaches vary widely, from before we’ve even touched the data to after we’ve trained a model (and everything in between).
The key lies in your data context, which I would define as the confluence of sample type, pipeline methodology, and modeling approach. If, for example, you desire to use differential privacy to query a SQL database full of private, sensitive data, there exists a well-formed solution for you (see Smartnoise’s private reader here). That implementation of the promise, however, enforces a markedly different solution than if you intend to use differential privacy to train a machine learning model on private, sensitive data.
Conclusion
DP is a huge space of solutions, and no one blog can succinctly describe the entire space. In Part 2, we’ll focus on one specific context: training a supervised learning model on private data at scale.
If you’re interested in learning more about MAIDAP and our work in Responsible AI, please check out our homepage. Every fall we hire a new cohort of university graduates studying AI/ML, so if you’re interested in building with us, please check out the Microsoft University Hiring website.